
By Cyril Morong on Feb 12 2006, 1:36p
http://www.beyondtheboxscore.com/2006/2/12/133645/296
One question that often comes up is "what is the relative value of on-base percentage (OBP) and slugging percentage (SLG)?" Is OBP 50% more important than SLG? Or 60%? Or something else? A stat called OPS simply adds the two, giving them equal weight. But maybe the weight should not be equal. For example, here is the regression equation of team runs per game for the years 2001-03:
R/G = 17.11*OBP + 11.13*SLG - 5.66
This makes OBP about 53% more important than SLG, a fairly typical result. But it is possible that OBP might be more important for certain positions in the lineup, like the leadoff batter. And for SLG, it might be more important for the cleanup hitter. To check this out, I ran a regression in which team runs per game was the dependent variable (DV) and the OBP and SLG of each lineup slot as the independent variables (IVs). OBP1 means the OBP of the leadoff batter, SLG3 means the SLG of the third place hitter, etc. I used data from Retrosheet for the 1989-2002 seasons. Retrosheet shows the stats for each team by lineup position. Below are the coefficient values for the IVs.
There is quite a variance. A point of OBP is worth about .003 runs per game from the leadoff man (a .021 increase in the leadoff OBP would be about .063 runs more per game or 10 for a whole season, which usually means about 1 win) The value of OBP is much less for the number 8 man. For the leadoff man, OBP is three times as important as SLG. For the cleanup hitter, they are almost the same. So this analysis shows that the relative values of OBP and SLG could be different depending on the lineup position of the batter in question.
Mark Pankin has already looked at this issue using a tool called Markov Chains. He presented his results at the SABR convention in 2004. His study is on line at:
http://www.pankin.com/sabr34.pdf
There could be multicollinearity in my analysis, meaning that the coefficient estimates are not as reliable as they could be because IVs are highly correlated with each other. I discuss what I did to detect multicollinearity below. But if this were a problem, I tried a different, but similar model where the IVs would likely be less correlated with each other.
Each lineup slot had 3 variables: walk percentage, hit percentage and extra-base percentage. For walks, hits, and extra-bases, the denominator was plate appearances (PAs). This is a little different than comparing OBP and SLG since OBP has PAs as the denominator and SLG has ABs. Also, by using extra-bases, it is a little like isolated power. SLG is not always as good measure of power because a guy who hits a single drives up his SLG. Isolated power is SLG - AVG, or extra-bases divided by ABs. Of course, here, I am using PAs. H1 is the hit% of the leadoff man, W1 is the walk% of the leadoff man, XB1 is the extra-base% of the leadoff man, etc. Here are the coefficient estimates:
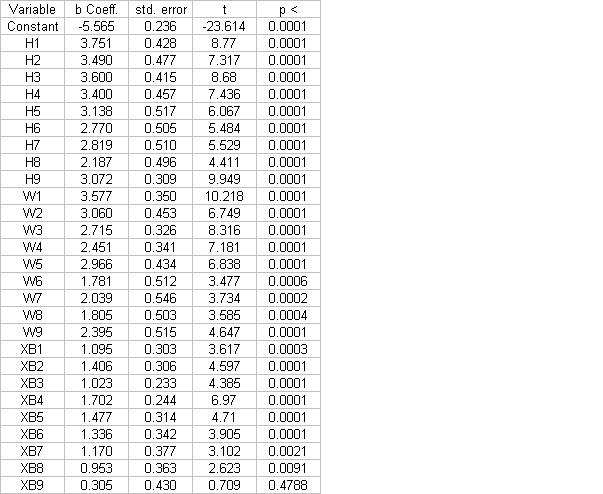
Again, there are some big differences. The value of a walk to the leadoff man is twice what it is for the number 6 man. The cleanup hitter has the highest extra-base value.
I did try some other variables. I had SBs and CS per game in the first model with OBP and SLG. Things were generally fine there except that in a couple of cases, the value of a CS was positive and in one case the value of a SB was negative. Why some lineup slots would have negative values for SBs or positive values for CS is not clear. I tried one regression with just the AL since they have the DH and a regular player bats ninth. The results seemed about the same. Email me if you want those.
Multicollinearity. In the first model with OBP and SLG, most of the correlations between the IVs were under .5. But some were higher and they were all the OBP and SLG for corresponding lineup positions. The correlation between OBP1 and SLG1 was .596. Those correlations ranged from .596 to .739, except for OBP9 and SLG9, which was very high, at .897. But in the second model, only one correlation between IVs was over .5 and that was H9 and XB9 at .648. The vast majority of the others were under .2.
Another way to check for multicollinearity is to run regressions in which one IV is a function of all of the other IVs. In the first model with OBP and SLG, the r-squared was generally in the .5-.6 range (that was 18 regressions). R-squared tells us how what percentage of the variation in the DV is explained by the model. There is a stat called the "variance inflation factor" or VIF. It is 1/(1 - r-squared). So if r-squared was .5, 1- .5 = .5. Then 1/.5 = 2. A couple of sources I looked at suggested that if the VIF is under 10, multicollinearity is not a problem. Most of these were about 2. One got close to 6 (that was SLG9). I did come across one source that said there is no rule about the value of VIF and multicollinearity.
For the second model, I only ran a couple of these regressions where one IV depended on all the others. The first one was W1 and the r-squared was only about .2. I tried XB9 (which corresponds a little to SLG9, the one that was closest to being a problem in the other model) and the r-squared was only about .4, which would mean a very low VIF of about 1.7.
Also, multicollinearity is supposed to be a problem where the standard errors of the coefficient estimates are high. This makes it hard for the estimates to be significant. But that was generally not the case here. One thing I don't know about is that there might be some kind of joint hypothesis about the VIF. Maybe if you have a large number of IVs it only takes a certain number to have a VIF over 2 or something like that for there to be a problem.